GPT wrapper apps are the ERC-20 of the AI hype wave. Entire startups ostensibly became obsolete overnight with the release of ChatGPT's Retrieval Plugin. Documus.app just takes it one step further by adding features to empower developer relations teams.
Any user of ChatGPT who has used it to answer questions about a corpus of text has no doubt found themselves wrangling with the tedium of copying multiple passages into the app, crafting a prompt about ChatGPT being “an expert assistant who answers questions about the text, just so…”, and then asking their questions. And forget about trying to load something like a novel project's documentation (Chat still thinks LangChain is a language exchange service on the blockchain), much less persist it for later answering; the token limit of GPT-3.5 made sure of that, and GPT-4's promise of a massive 32k token limit still doesn't solve the problem.
Leveraging Documus for code completion, we can level the learning curve for developers of all skill levels, while reducing the bounce rate for new projects, and gain actionable insights about their users in a meaningful way.
Enter embeddings and vector search (and the hoard of people who decided that OpenAI's tutorials should be turned into a startup). For the unacquainted, embeddings allow words, sentences, paragraphs, etc (essentially sequences of words) to be converted to a very convenient type of mathematical structure called a vector, which has properties that allow it to be compared (among other things) with other vectors. The trick is, the way in which those sentences and paragraphs are turned into vectors captures the semantic properties of the sentence/etc. so that similarity of vectors translates to similarity of the underlying text that was “vectorized”.
Once you have “vectorized” or embedded pieces of a corpus of a text, you can do things like hand it a question (which gets embedded), and look in the “neighborhood” of it in the embedding space to find nearby vectors which correspond to pieces of the text you're asking questions about which are most semantically similar to your textual question. This is done with a vector search algorithm. A collection of these “nearby” chunks are appended to the beginning of a GPT-3.5/4 query as “context” (like what you'd do in the tedious workflow I first mentioned. The GPT completions (or chat) API works its magic, and now you have an actual assistant that can see the whole body of text.
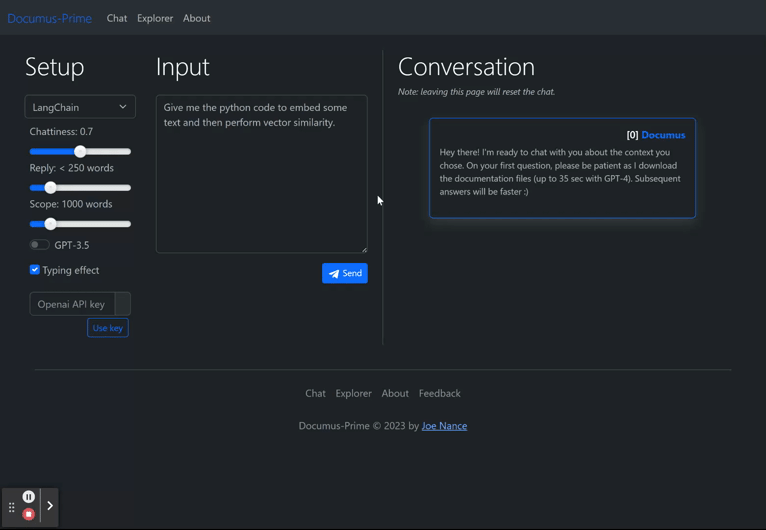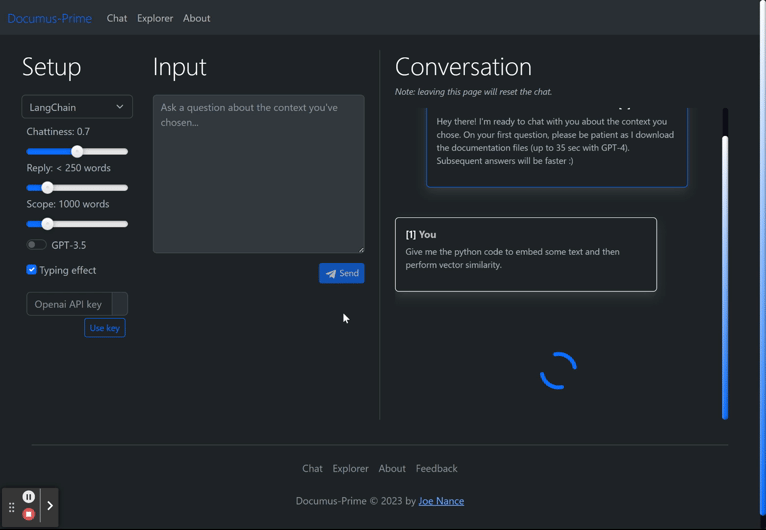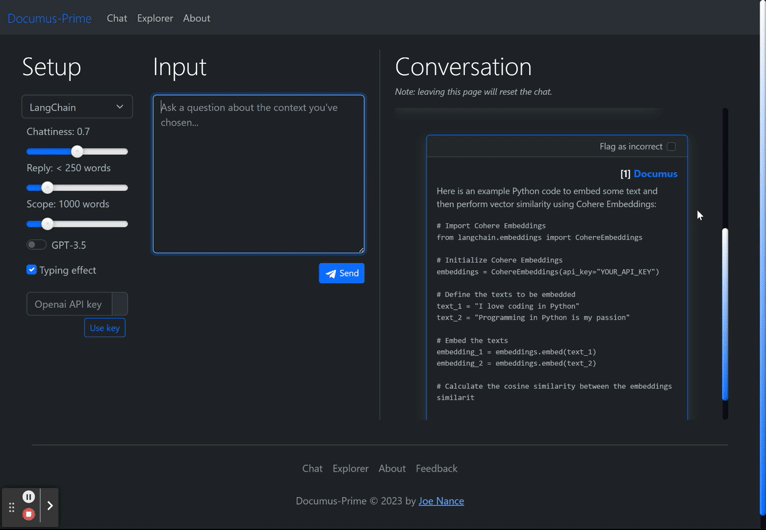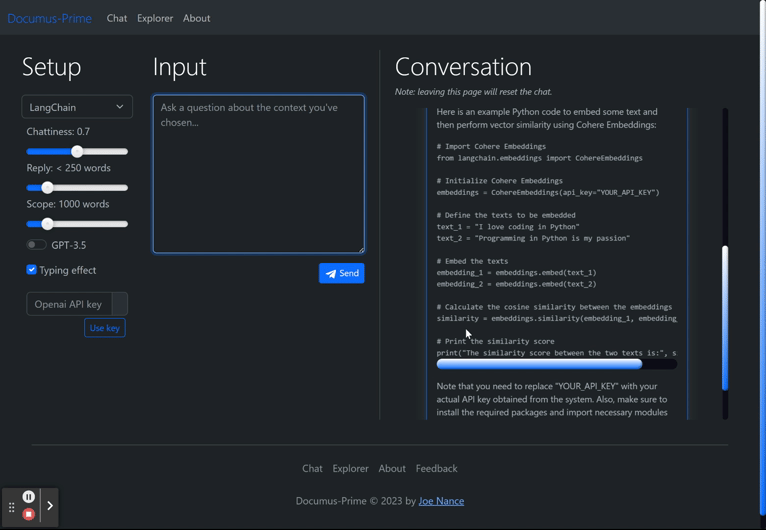
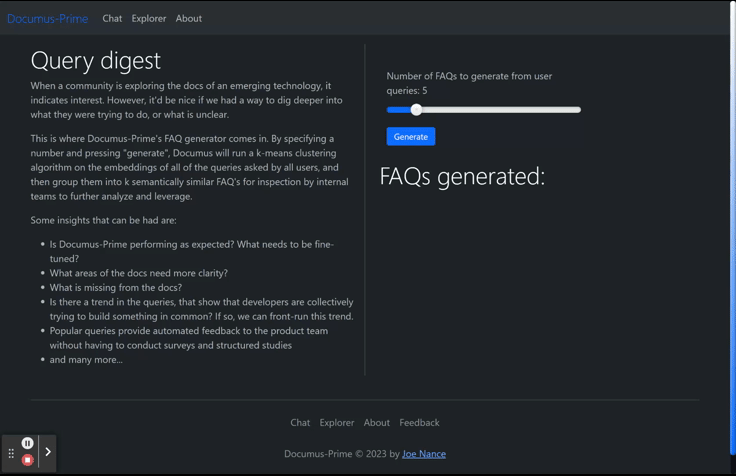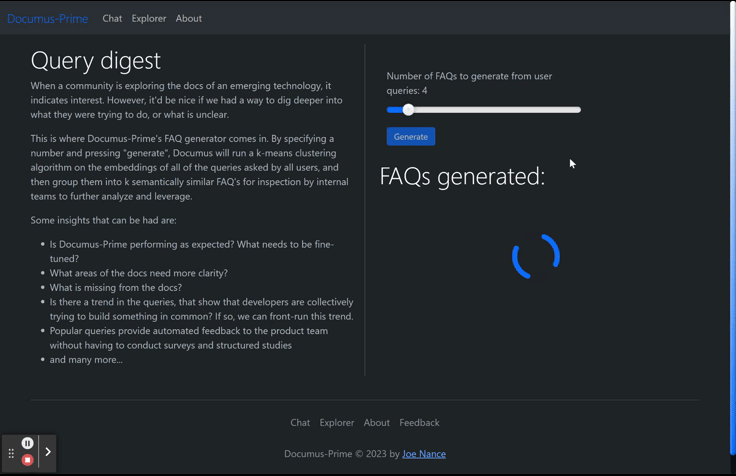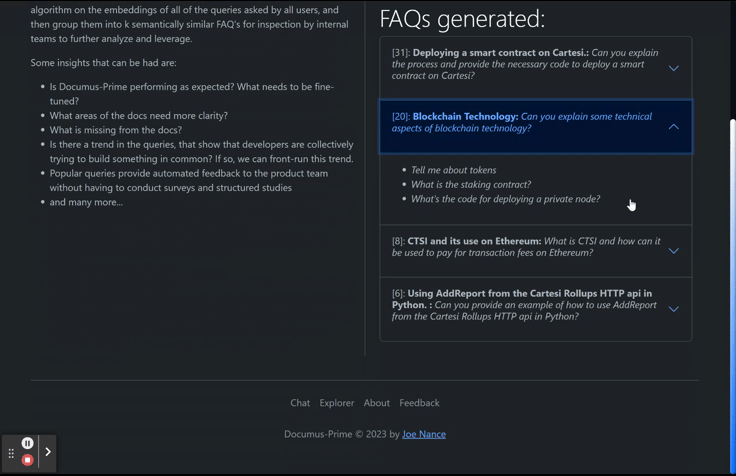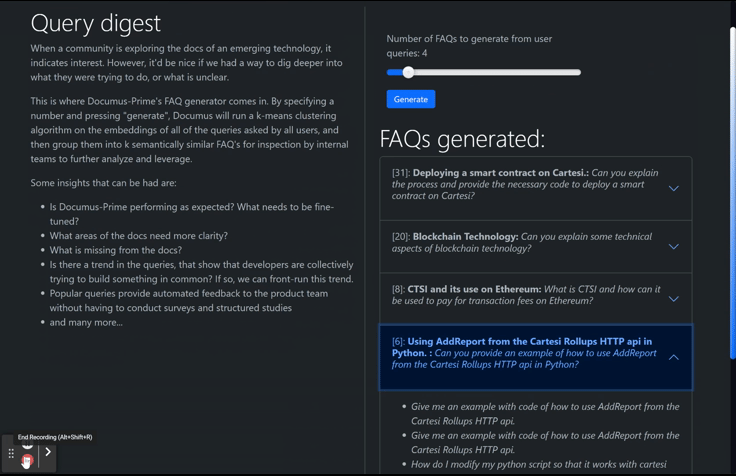
When I built Documus, I cleaned and embedded over 13 different technical projects' documentation (Arbitrum, Avalanche, Cardano, Cartesi, Chainlink, Ethereum, Gnosis, The Graph, Lang Chain, Optimism, Polygon (Matic) Solana, and more...) on which GPT-3.5/4 may not have been trained, so that developer relation (“devrel”) teams can level the learning curve for all skill levels. It works especially well with GPT3.5's code completion, allowing unfamiliar devs to spin up projects in record time, when they otherwise would have bounced or given up. As mentioned, this is nothing new. Many startups were founded on this idea of “document retrieval” alone (with convenient features like drag-and-drop documents, etc.). However, the real value add of Documus is that on the backend, it is analyzing sessions and queries, implementing k-means clustering so that devrel teams can generate a dynamic FAQ list (however long they want) of what their users are asking.
Documus has helped teams not only increase adoption of their tech, but the FAQ generation feature is an ostensible feedback loop to the product and technical writing teams to gain insight to the pain points of of their tech, and to identify the use cases that developers are using their tech for, allowing them to front-run feature development on their roadmaps.
So, no- developing yet another document retrieval app is nothing to call the news papers about; in fact, in many ways, they're the ERC-20 token of this wave of AI hype. However, by augmenting it with analytical features, it transcends meme-app status to become a powerful tool for devrel and product teams learn who their users are, what they are struggling with, and how they really are using their tech.
Notice: for source code inquiries, reach out to me on Linkedin